💡 这节课会带给你
- 了解提示工程的跨时代意义,改「精确逻辑」习惯为「模糊执行」习惯
- 掌握提示工程的核心方法论,比 99% 的人达成更好效果
- 掌握提示调优的基本方法,了解它在实际生产中的应用
- 掌握防止Prompt注入的方法,AI更安全
开始上课!
1.什么是提示工程(Prompt Engineering)
提示工程也叫「指令工程」。
- Prompt 就是你发给 ChatGPT 的指令,比如「讲个笑话」、「用 Python 编个贪吃蛇游戏」、「给男/女朋友写封情书」等
- 貌似简单,但意义非凡
- Prompt 是 AGI 时代的「编程语言」
- Prompt 工程是 AGI 时代的「软件工程」
- 提示工程师是 AGI 时代的「程序员」
- 学会提示工程,就像学用鼠标、键盘一样,是 AGI 时代的基本技能
- 专门的「提示工程师」不会长久,因为每个人都要会「提示工程」
思考:
如果人人都会,那我们的优势是什么?
1.1、我们在「提示工程」上的优势
我们懂「大模型只会基于概率生成下一个字」这个原理,所以知道:
- 为什么有的指令有效,有的指令无效
- 为什么同样的指令有时有效,有时无效
- 怎么提升指令有效的概率
我们懂编程:
- 知道哪些问题用提示工程解决更高效,哪些用传统编程更高效
- 能完成和业务系统的对接,把效能发挥到极致
1.2、使用 Prompt 的两种目的
- 获得具体问题的具体结果,比如「我该学 Vue 还是 React?」「PHP 为什么是最好的语言?」
- 固化一套 Prompt 到程序中,成为系统功能的一部分,比如「每天生成本公司的简报」「AI 客服系统」「基于公司知识库的问答」
前者主要通过 ChatGPT、ChatALL 这样的界面操作。后者就要动代码了。我们会专注于后者,因为:
- 后者更难,掌握后能轻松搞定前者
- 后者是我们的独特优势
1.3、Prompt 调优
找到好的 prompt 是个持续迭代的过程,需要不断调优。
- 从人的视角:说清楚自己到底想要什么
- 从机器的视角:不是每个细节它都能猜到你的想法,它猜不到的,你需要详细说
- 从模型的视角:不是每种说法它都能完美理解,需要尝试和技巧
二、Prompt 的构成
- 指示: 对任务进行描述
- 上下文: 给出与任务相关的其它背景信息(尤其在多轮交互中)
- 例子: 必要时给出举例,学术中称为 one-shot learning, few-shot learning 或 in-context learning;实践证明其对输出正确性有帮助
- 输入: 任务的输入信息;在提示词中明确的标识出输入
- 输出: 输出的格式描述,以便后继模块自动解析模型的输出结果,比如(JSON、XML)
2.1、设定一个业务场景来讲解上述知识
业务场景:办理流量包的智能客服
流量包产品:
| 名称 | 流量(G/月) | 价格(元/月) | 适用人群 |
|---|---|---|---|
| 经济套餐 | 10 | 50 | 无限制 |
| 畅游套餐 | 100 | 180 | 无限制 |
| 无限套餐 | 1000 | 300 | 无限制 |
| 校园套餐 | 200 | 150 | 在校生 |
2.2、对话系统的基本模块(简介)

对话流程举例:
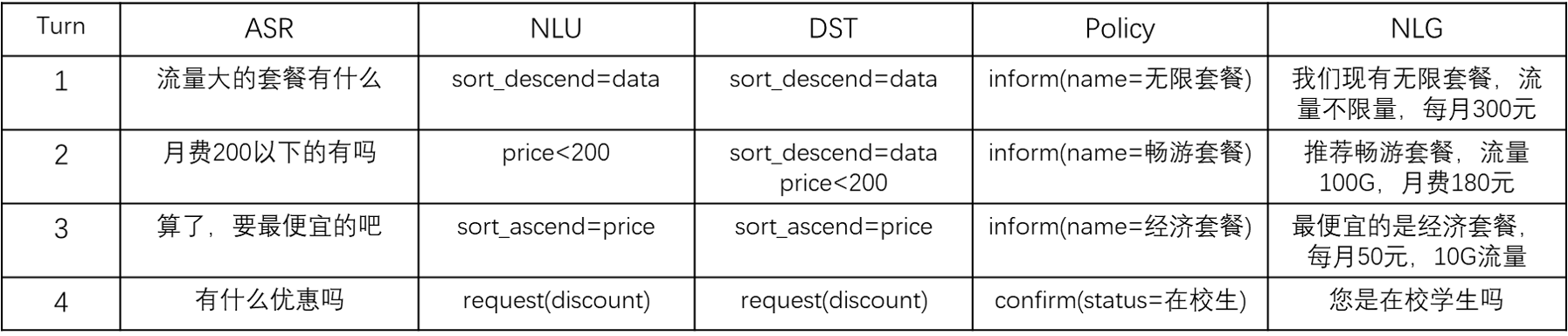
2.3、用Prompt实现上述模块功能
环境搭建
调试 prompt 的过程其实在图形界面里开始会更方便,但为了方便演示和大家上手体验,我们直接在代码里调试。
# 加载环境变量import openaiimport osfrom dotenv import load_dotenv, find_dotenv_ = load_dotenv(find_dotenv()) # 读取本地 .env 文件,里面定义了 OPENAI_API_KEYopenai.api_key = os.getenv('OPENAI_API_KEY')
# 基于 prompt 生成文本def get_completion(prompt, model="gpt-3.5-turbo"):messages = [{"role": "user", "content": prompt}]response = openai.ChatCompletion.create(model=model,messages=messages,temperature=0, # 模型输出的随机性,0 表示随机性最小)return response.choices[0].message["content"]
2.3.1、实现一个NLU
任务描述+输入
# 任务描述instruction = """你的任务是识别用户对手机流量套餐产品的选择条件。每种流量套餐产品包含三个属性:名称,月费价格,月流量。根据用户输入,识别用户在上述三种属性上的倾向。"""# 用户输入input_text = """办个100G的套餐。"""# 这是系统预置的 prompt。魔法咒语的秘密都在这里prompt = f"""{instruction}# 用户输入:{input_text}"""response = get_completion(prompt)print(response)
用户在流量套餐产品的选择条件上的倾向为:
- 名称:用户倾向选择100G的套餐。
- 月费价格:用户未提及对月费价格的倾向。
- 月流量:用户倾向选择100G的套餐。
约定输出格式
# 输出描述output_format = """以JSON格式输出"""# 稍微调整下咒语prompt = f"""{instruction}{output_format}用户输入:{input_text}"""response = get_completion(prompt)print(response)
{
“名称”: “100G套餐”,
“月费价格”: “未知”,
“月流量”: “100G”
}
把描述定义的更精细
instruction = """你的任务是识别用户对手机流量套餐产品的选择条件。每种流量套餐产品包含三个属性:名称(name),月费价格(price),月流量(data)。根据用户输入,识别用户在上述三种属性上的倾向。"""# 输出描述output_format = """以JSON格式输出。1. name字段的取值为string类型,取值必须为以下之一:经济套餐、畅游套餐、无限套餐、校园套餐 或 null;2. price字段的取值为一个结构体 或 null,包含两个字段:(1) operator, string类型,取值范围:'<='(小于等于), '>=' (大于等于), '=='(等于)(2) value, int类型3. data字段的取值为取值为一个结构体 或 null,包含两个字段:(1) operator, string类型,取值范围:'<='(小于等于), '>=' (大于等于), '=='(等于)(2) value, int类型或string类型,string类型只能是'无上限'4. 用户的意图可以包含按price或data排序,以sort字段标识,取值为一个结构体:(1) 结构体中以"ordering"="descend"表示按降序排序,以"value"字段存储待排序的字段(2) 结构体中以"ordering"="ascend"表示按升序排序,以"value"字段存储待排序的字段只输出中只包含用户提及的字段,不要猜测任何用户未直接提及的字段,不输出值为null的字段。"""#input_text = "办个100G以上的套餐"#input_text = "我要无限量套餐"input_text = "有没有便宜的套餐"prompt = f"""{instruction}{output_format}用户输入:{input_text}"""response = get_completion(prompt)print(response)
{
“name”: “经济套餐”
}
加入例子:让输出更稳定
examples = """便宜的套餐:{"sort":{"ordering"="ascend","value"="price"}}有没有不限流量的:{"data":{"operator":"==","value":"无上限"}}流量大的:{"sort":{"ordering"="descend","value"="data"}}100G以上流量的套餐最便宜的是哪个:{"sort":{"ordering"="ascend","value"="price"},"data":{"operator":">=","value":100}}月费不超过200的:{"price":{"operator":"<=","value":200}}就要月费180那个套餐:{"price":{"operator":"==","value":180}}经济套餐:{"name":"经济套餐"}"""#input_text = "办个200G的套餐"input_text = "有没有流量大的套餐"#input_text = "200元以下,流量大的套餐有啥"#input_text = "你说那个10G的套餐,叫啥名字"prompt = f"""{instruction}{output_format}例如:{examples}用户输入:{input_text}"""response = get_completion(prompt)print(response)
{“sort”:{“ordering”:”descend”,”value”:”data”}}
改变习惯,优先用 Prompt 解决问题
用好prompt可以减轻预处理和后处理的工作量和复杂度。
2.3.2、实现上下文DST
在Prompt中加入上下文
instruction = """你的任务是识别用户对手机流量套餐产品的选择条件。每种流量套餐产品包含三个属性:名称(name),月费价格(price),月流量(data)。根据对话上下文,识别用户在上述属性上的倾向。识别结果要包含整个对话的信息。"""# 输出描述output_format = """以JSON格式输出。1. name字段的取值为string类型,取值必须为以下之一:经济套餐、畅游套餐、无限套餐、校园套餐 或 null;2. price字段的取值为一个结构体 或 null,包含两个字段:(1) operator, string类型,取值范围:'<='(小于等于), '>=' (大于等于), '=='(等于)(2) value, int类型3. data字段的取值为取值为一个结构体 或 null,包含两个字段:(1) operator, string类型,取值范围:'<='(小于等于), '>=' (大于等于), '=='(等于)(2) value, int类型或string类型,string类型只能是'无上限'4. 用户的意图可以包含按price或data排序,以sort字段标识,取值为一个结构体:(1) 结构体中以"ordering"="descend"表示按降序排序,以"value"字段存储待排序的字段(2) 结构体中以"ordering"="ascend"表示按升序排序,以"value"字段存储待排序的字段只输出中只包含用户提及的字段,不要猜测任何用户未直接提及的字段。不要输出值为null的字段。"""#DO NOT OUTPUT NULL-VALUED FIELD!examples = """客服:有什么可以帮您用户:100G套餐有什么{"data":{"operator":">=","value":100}}客服:有什么可以帮您用户:100G套餐有什么客服:我们现在有无限套餐,不限流量,月费300元用户:太贵了,有200元以内的不{"data":{"operator":">=","value":100},"price":{"operator":"<=","value":200}}客服:有什么可以帮您用户:便宜的套餐有什么客服:我们现在有经济套餐,每月50元,10G流量用户:100G以上的有什么{"data":{"operator":">=","value":100},"sort":{"ordering"="ascend","value"="price"}}客服:有什么可以帮您用户:100G以上的套餐有什么客服:我们现在有畅游套餐,流量100G,月费180元用户:流量最多的呢{"sort":{"ordering"="descend","value"="data"},"data":{"operator":">=","value":100}}"""input_text="哪个便宜"#input_text="无限量哪个多少钱"#input_text="流量最大的多少钱"context = f"""客服:有什么可以帮您用户:有什么100G以上的套餐推荐客服:我们有畅游套餐和无限套餐,您有什么价格倾向吗用户:{input_text}"""prompt = f"""{instruction}{output_format}{examples}{context}"""response = get_completion(prompt)print(response)
{“sort”:{“ordering”=”ascend”,”value”=”price”},”data”:
{“operator”:”>=”,”value”:100}}
- 优点: 节省开发量
- 缺点: 调优相对复杂,最好用动态例子(讲Embedding时再review这个点)
- 优点: DST环节可控性更高
- 缺点: 需要结合业务know-how设计状态更新机制(解冲突)
2.3.3、实现NLG和对话策略
我们先把刚才的能力串起来,构建一个简单的客服机器人
# 加载环境变量import openaiimport os, json, copyfrom dotenv import load_dotenv, find_dotenv_ = load_dotenv(find_dotenv()) # 读取本地 .env 文件,里面定义了 OPENAI_API_KEYopenai.api_key = os.getenv('OPENAI_API_KEY')instruction = """你的任务是识别用户对手机流量套餐产品的选择条件。每种流量套餐产品包含三个属性:名称(name),月费价格(price),月流量(data)。根据用户输入,识别用户在上述三种属性上的倾向。"""# 输出描述output_format = """以JSON格式输出。1. name字段的取值为string类型,取值必须为以下之一:经济套餐、畅游套餐、无限套餐、校园套餐 或 null;2. price字段的取值为一个结构体 或 null,包含两个字段:(1) operator, string类型,取值范围:'<='(小于等于), '>=' (大于等于), '=='(等于)(2) value, int类型3. data字段的取值为取值为一个结构体 或 null,包含两个字段:(1) operator, string类型,取值范围:'<='(小于等于), '>=' (大于等于), '=='(等于)(2) value, int类型或string类型,string类型只能是'无上限'4. 用户的意图可以包含按price或data排序,以sort字段标识,取值为一个结构体:(1) 结构体中以"ordering"="descend"表示按降序排序,以"value"字段存储待排序的字段(2) 结构体中以"ordering"="ascend"表示按升序排序,以"value"字段存储待排序的字段只输出中只包含用户提及的字段,不要猜测任何用户未直接提及的字段。DO NOT OUTPUT NULL-VALUED FIELD! 确保输出能被json.loads加载。"""examples = """便宜的套餐:{"sort":{"ordering"="ascend","value"="price"}}有没有不限流量的:{"data":{"operator":"==","value":"无上限"}}流量大的:{"sort":{"ordering"="descend","value"="data"}}100G以上流量的套餐最便宜的是哪个:{"sort":{"ordering"="ascend","value"="price"},"data":{"operator":">=","value":100}}月费不超过200的:{"price":{"operator":"<=","value":200}}就要月费180那个套餐:{"price":{"operator":"==","value":180}}经济套餐:{"name":"经济套餐"}"""class NLU:def __init__(self):self.prompt_template = f"{instruction}\n\n{output_format}\n\n{examples}\n\n用户输入:\n__INPUT__"def _get_completion(self, prompt, model="gpt-3.5-turbo"):messages = [{"role": "user", "content": prompt}]response = openai.ChatCompletion.create(model=model,messages=messages,temperature=0, # 模型输出的随机性,0 表示随机性最小)semantics = json.loads(response.choices[0].message["content"])return { k:v for k,v in semantics.items() if v }def parse(self, user_input):prompt = self.prompt_template.replace("__INPUT__",user_input)return self._get_completion(prompt)class DST:def __init__(self):passdef update(self, state, nlu_semantics):if "name" in nlu_semantics:state.clear()if "sort" in nlu_semantics:slot = nlu_semantics["sort"]["value"]if slot in state and state[slot]["operator"] == "==":del state[slot]for k, v in nlu_semantics.items():state[k] = vreturn stateclass MockedDB:def __init__(self):self.data = [{"name":"经济套餐","price":50,"data":10,"requirement":None},{"name":"畅游套餐","price":180,"data":100,"requirement":None},{"name":"无限套餐","price":300,"data":1000,"requirement":None},{"name":"校园套餐","price":150,"data":200,"requirement":"在校生"},]def retrieve(self, **kwargs):records = []for r in self.data:select = Trueif r["requirement"]:if "status" not in kwargs or kwargs["status"]!=r["requirement"]:continuefor k, v in kwargs.items():if k == "sort":continueif k == "data" and v["value"] == "无上限":if r[k] != 1000:select = Falsebreakif "operator" in v:if not eval(str(r[k])+v["operator"]+str(v["value"])):select = Falsebreakelif str(r[k])!=str(v):select = Falsebreakif select:records.append(r)if len(records) <= 1:return recordskey = "price"reverse = Falseif "sort" in kwargs:key = kwargs["sort"]["value"]reverse = kwargs["sort"]["ordering"] == "descend"return sorted(records,key=lambda x: x[key] ,reverse=reverse)class DialogManager:def __init__(self, prompt_templates):self.state = {}self.session = [{"role": "system","content": "你是一个手机流量套餐的客服代表,你叫小瓜。可以帮助用户选择最合适的流量套餐产品。"}]self.nlu = NLU()self.dst = DST()self.db = MockedDB()self.prompt_templates = prompt_templatesdef _wrap(self,user_input,records):if records:prompt = self.prompt_templates["recommand"].replace("__INPUT__",user_input)r = records[0]for k,v in r.items():prompt = prompt.replace(f"__{k.upper()}__",str(v))else:prompt = self.prompt_templates["not_found"].replace("__INPUT__",user_input)for k,v in self.state.items():if "operator" in v:prompt = prompt.replace(f"__{k.upper()}__",v["operator"]+str(v["value"]))else:prompt = prompt.replace(f"__{k.upper()}__",str(v))return promptdef _call_chatgpt(self, prompt, model="gpt-3.5-turbo"):session = copy.deepcopy(self.session)session.append({"role": "user", "content": prompt})response = openai.ChatCompletion.create(model=model,messages=session,temperature=0,)return response.choices[0].message["content"]def run(self, user_input):#调用NLU获得语义解析semantics = self.nlu.parse(user_input)print("===semantics===")print(semantics)#调用DST更新多轮状态self.state = self.dst.update(self.state,semantics)print("===state===")print(self.state)#根据状态检索DB,获得满足条件的候选records = self.db.retrieve(**self.state)#拼装prompt调用chatgptprompt_for_chatgpt = self._wrap(user_input, records)print("===gpt-prompt===")print(prompt_for_chatgpt)#调用chatgpt获得回复response = self._call_chatgpt(prompt_for_chatgpt)#将当前用户输入和系统回复维护入chatgpt的sessionself.session.append({"role": "user", "content": user_input})self.session.append({"role": "assistant", "content": response})return response
将垂直知识加入prompt,以使其准确回答
prompt_templates = {"recommand" : "用户说:__INPUT__ \n\n向用户介绍如下产品:__NAME__,月费__PRICE__元,每月流量__DATA__G。","not_found" : "用户说:__INPUT__ \n\n没有找到满足__PRICE__元价位__DATA__G流量的产品,询问用户是否有其他选择倾向。"}dm = DialogManager(prompt_templates)
response = dm.run("流量大的")#response = dm.run("300太贵了,200元以内有吗")print("===response===")print(response)
===semantics=== {‘price’: {‘operator’: ‘<=’, ‘value’: 200}} ===state=== {‘sort’: {‘ordering’: ‘descend’, ‘value’: ‘data’}, ‘price’: {‘operator’: ‘<=’, ‘value’: 200}} ===gpt-prompt=== 用户说:300太贵了,200元以内有吗
向用户介绍如下产品:畅游套餐,月费180元,每月流量100G。 ===response=== 小瓜:非常抱歉,我们的无限套餐可能确实有些贵了。如果您的预算在200元以内,我可以向您推荐我们的畅游套餐。这个套餐每月只需支付180元,您将享受到每月100G的流量。虽然相比无限套餐流量稍少一些,但对于一般的上网需求来说已经足够了。如果您对这个套餐感兴趣,我可以帮您办理。还有其他的套餐选项,您有其他的需求吗?
增加约束:改变语气、口吻
ext = "很口语,亲切一些。不用说“抱歉”。直接给出回答,不用在前面加“小瓜说:”。NO COMMENTS. NO ACKNOWLEDGEMENTS."prompt_templates = { k : v+ext for k, v in prompt_templates.items() }dm = DialogManager(prompt_templates)
#response = dm.run("流量大的")response = dm.run("300太贵了,200元以内有吗")print("===response===")print(response)
===semantics===
{‘price’: {‘operator’: ‘<=’, ‘value’: 200}}
===state===
{‘sort’: {‘ordering’: ‘descend’, ‘value’: ‘data’}, ‘price’: {‘operator’: ‘<=’, ‘value’: 200}}
===gpt-prompt===
用户说:300太贵了,200元以内有吗向用户介绍如下产品:畅游套餐,月费180元,每月流量100G。很口语,亲切一些。不用说“抱歉”。直接给出回答,不用在前面加“小瓜说:”。NO COMMENTS. NO ACKNOWLEDGEMENTS.
===response===
畅游套餐是您的不错选择!它每月只需180元,您将享受到100G的流量。这样您可以畅快地上网、观看视频和使用各种应用,而不用担心流量不够用。如果您对这个套餐感兴趣或有其他问题,随时告诉我哦!
以例子的形式实现对话策略
ext = "\n\n遇到类似问题,请参照以下回答:\n你们流量包太贵了\n亲,我们都是全省统一价哦。"prompt_templates = { k : v+ext for k, v in prompt_templates.items() }dm = DialogManager(prompt_templates)
response = dm.run("这流量包太贵了")print("===response===")print(response)
===semantics===
{‘sort’: {‘ordering’: ‘ascend’, ‘value’: ‘price’}}
===state===
{‘sort’: {‘ordering’: ‘ascend’, ‘value’: ‘price’}}
===gpt-prompt===
用户说:这流量包太贵了向用户介绍如下产品:经济套餐,月费50元,每月流量10G。很口语,亲切一些。不用说“抱歉”。直接给出回答,不用在前面加“小瓜说:”。NO COMMENTS. NO ACKNOWLEDGEMENTS.
遇到类似问题,请参照以下回答:
你们流量包太贵了
亲,我们都是全省统一价哦。 ===response===
我们了解您的担忧,但是我们的流量套餐价格都是全省统一的哦。不过,如果您觉得当前的流量包价格有些高,我们还有一个经济套餐,每月只需支付50元,就可以享受10G的流量。这个套餐性价比非常高,您可以考虑一下哦。如果您有其他需求或者疑问,随时告诉我,我会尽力帮助您的。
- 这里的例子可以动态添加
- 具体方法我们放在LangChain课程中结合Embedding一起讲解
- 尝试自己通过NLU和Policy实现给在校生推荐“校园套餐”
